机器学习开始前的准备工作
本部分列出了一些模型构建前针对手头数据的准备工作,包括:
- 数据划分:2 初始数据划分。
- 数值变量和分类变量的预处理步骤。 4 数值变量转换 和 5 分类变量处理。
- 缺失值处理:3 缺失值处理。
- 变量的选择和过滤:6 嵌入法。
- 交互作用与非线性关系的处理:7 线性与非线性特征。
常见的机器学习算法所需预处理步骤
除数据清洗、数据划分等通用的核心预处理步骤外,不同机器学习算法对数据预处理的需求也有所不同。
预处理方法和步骤的选择通常取决于所使用的模型。某些模型对数据的分布、尺度和相关性更为敏感,而其他模型则更为稳健。了解不同模型对预处理的需求,有助于提高模型的性能和预测能力。
tidymodels 中推荐的模型预处理步骤
tidymodels中针对不同类型模型推荐的基本预处理步骤,这些步骤可以作为起点,具体的预处理需求可能因数据集和分析目标而异,主要包括:
- dummy:定性预测变量是否需要进行数值编码(例如,通过虚拟变量或其他方法)?
tidymodels中所有的哑变量和编码可参看,https://recipes.tidymodels.org/reference/index.html#step-functions-dummy-variables-and-encodings
- zv:是否应移除只有一个唯一值的列(即零方差变量)?
- https://recipes.tidymodels.org/reference/index.html#step-functions-filters
- impute:如果某些预测变量存在缺失值,是否应通过插补法对其进行估计? 3 缺失值处理。
tidymodels中所有的缺失值插补函数可参看,https://recipes.tidymodels.org/reference/index.html#step-functions-imputation
- decorrelate:如果存在相关的预测变量,是否应减轻这种相关性?这可能意味着筛选掉一些预测变量、使用主成分分析或基于模型的技术(例如正则化)。
- https://recipes.tidymodels.org/reference/index.html#step-functions-filters
- normalize:是否应对预测变量进行中心化和标准化处理? ?sec-sec-normalization。
- transform:将预测变量转换为更对称的形式是否有帮助?对数变换。
要了解更多关于这些模型以及其他可能可用的模型的信息,请参看 https://www.tidymodels.org/find/parsnip/.
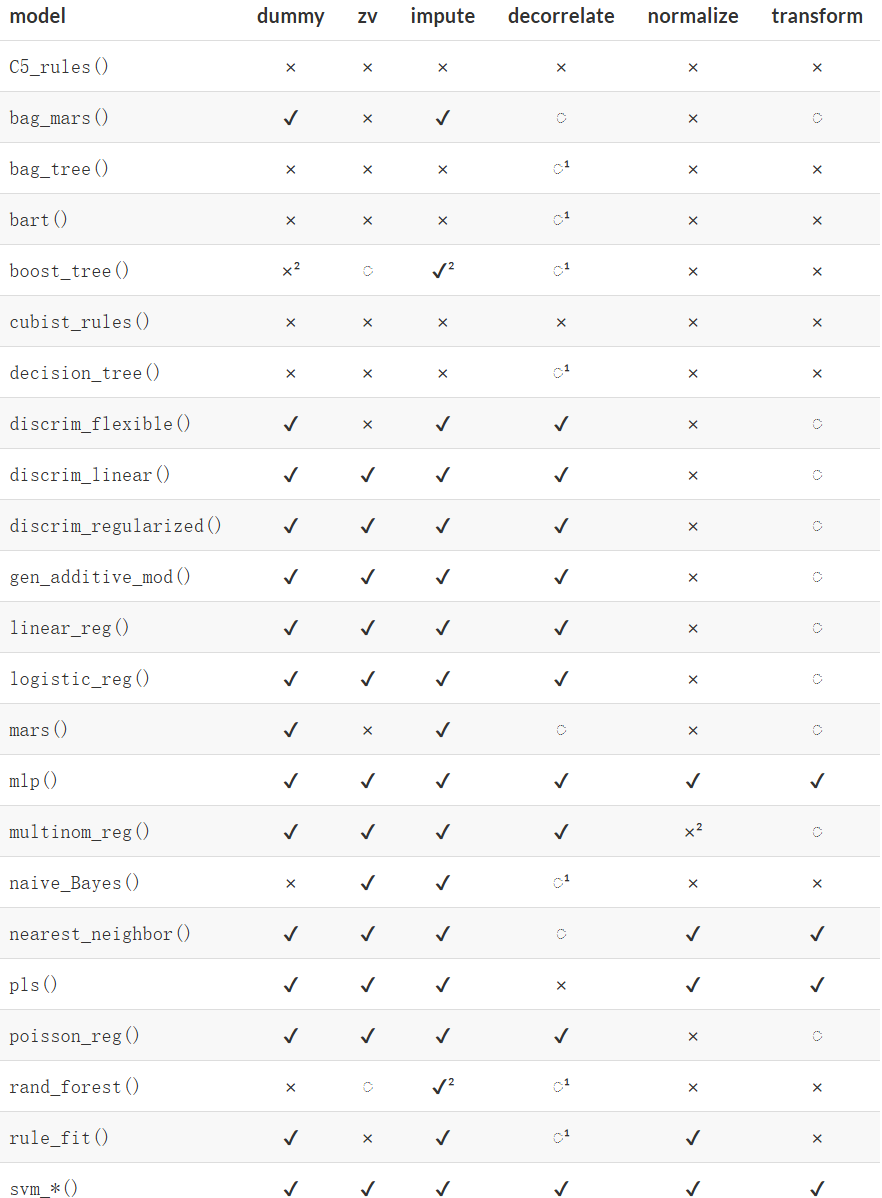
上图中:
去除具有相关性的预测变量可能对提高模型性能没有帮助,但较少的预测变量确实可以改善变量重要性分数的估计。
这些方法的选择取决于具体情况。理论上:
- 任何基于树的模型都不需要插补。然而,许多树集成的实现需要插补。
- 基于树的提升方法通常不需要创建虚拟变量,但使用
xgboost包为引擎时则需要创建。