22 K-最邻近算法
本章使用一个模拟的default违约数据集,介绍三种应用最广泛的分类方法:逻辑斯谛回归、线性判别分析、K近邻算法。重点聚焦KNN算法。
关于分类模型评估的指标,具体可参看 ?sec-measure-classification
22.1 Knn算法
KNN算法是一种基于实例的学习方法,它的核心思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。简单的说,就是找K个距离待遇测样本最近的点,然后根据这几个点的类别来确定新样本的类别。
22.2 逻辑斯谛回归
- 逻辑斯谛回归模型的输出结果与线性回归的输出结果类似,均可以通过p值的大小判断是否接受零假设。
- 逻辑斯谛回归 可通过设定哑变量的方式分析定性预测变量。
- 与线性回归类似,逻辑斯谛回归中如果预测变量之间存在多重共线性,会导致模型的不稳定性。
22.3 判别分析
22.3.1 线性判别分析
- 线性判别分析是一种监督学习方法,用于分类问题。
- 线性判别分析的目标是找到一个线性组合,使得不同类别的数据在这个线性组合上的投影尽可能远离,同一类别的数据尽可能接近。
- 除了分类外,线性判别分析还可用于数据的降维。
22.3.2 二次判别分析
- 拟合非线性关系时,可以用到二次判别分析,它时线性判别分析的一个变体。
- 分类问题常用灵敏度和特异度作为模型能力的测试指标。
- 灵敏度(sensitivity):指的是模型对正例的识别能力。
- 特异度(specificity):指的是模型对负例的识别能力。
- 分类问题中,如何设定合理的分类阈值非常重要。
- 通常情况下,分类阈值设定为0.5。
- 但是在实际应用中,根据业务需求,可以根据灵敏度和特异度的需求,调整分类阈值。
-
ROC曲线可以很好的展示分类模型的性能。-
ROC曲线的横轴是假正例的比例,即真实值为被错误判断的比例;纵轴是真正例的比例,即真实值被正确判断的比例。 -
ROC曲线下的面积AUC越大,说明模型的性能越好。通常情况下,我们认为一个分类模型的AUC至少应大于0.5,
-
- 如何确定一个适合的模型光滑度(模型选择),并评价这个模型的表现(模型评价)将在重抽样章节详细介绍(?sec-resampling)
22.4 KNN模型实验-传统方法-kknn包
22.4.1 数据准备
load(
file = "D:/Document/0.Study R/6.Tidymodels-with-R/data/datasetsayue/pimadiabetes.rdata"
)
dim(pimadiabetes)[1] 768 9str(pimadiabetes)'data.frame': 768 obs. of 9 variables:
$ pregnant: num 6 1 8 1 0 5 3 10 2 8 ...
$ glucose : num 148 85 183 89 137 116 78 115 197 125 ...
$ pressure: num 72 66 64 66 40 ...
$ triceps : num 35 29 22.9 23 35 ...
$ insulin : num 202.2 64.6 217.1 94 168 ...
$ mass : num 33.6 26.6 23.3 28.1 43.1 ...
$ pedigree: num 0.627 0.351 0.672 0.167 2.288 ...
$ age : num 50 31 32 21 33 30 26 29 53 54 ...
$ diabetes: Factor w/ 2 levels "pos","neg": 2 1 2 1 2 1 2 1 2 2 ...各个变量的含义: - pregnant:怀孕次数 - glucose:血浆葡萄糖浓度(葡萄糖耐量试验) - pressure:舒张压(毫米汞柱) - triceps:三头肌皮褶厚度(mm) - insulin:2 小时血清胰岛素(mu U/ml) - mass:BMI - pedigree:糖尿病谱系功能,是一种用于预测糖尿病发病风险的指标,该指标是基于 家族史的糖尿病遗传风险因素的计算得出的。它计算了患者的家族成员是否患有糖尿 病以及他们与患者的亲缘关系,从而得出一个综合评分,用于预测患糖尿病的概率。 - age:年龄 - diabetes:是否有糖尿病
pimadiabetes <- pimadiabetes %>%
mutate(
across(where(is.numeric), \(x) scale(x))
)
str(pimadiabetes)'data.frame': 768 obs. of 9 variables:
$ pregnant: num [1:768, 1] 0.64 -0.844 1.233 -0.844 -1.141 ...
..- attr(*, "scaled:center")= num 3.85
..- attr(*, "scaled:scale")= num 3.37
$ glucose : num [1:768, 1] 0.863 -1.203 2.011 -1.072 0.503 ...
..- attr(*, "scaled:center")= num 122
..- attr(*, "scaled:scale")= num 30.5
$ pressure: num [1:768, 1] -0.0314 -0.5244 -0.6887 -0.5244 -2.6607 ...
..- attr(*, "scaled:center")= num 72.4
..- attr(*, "scaled:scale")= num 12.2
$ triceps : num [1:768, 1] 0.63124 -0.00231 -0.64853 -0.63586 0.63124 ...
..- attr(*, "scaled:center")= num 29
..- attr(*, "scaled:scale")= num 9.47
$ insulin : num [1:768, 1] 0.478 -0.933 0.63 -0.631 0.127 ...
..- attr(*, "scaled:center")= num 156
..- attr(*, "scaled:scale")= num 97.6
$ mass : num [1:768, 1] 0.172 -0.844 -1.323 -0.626 1.551 ...
..- attr(*, "scaled:center")= num 32.4
..- attr(*, "scaled:scale")= num 6.89
$ pedigree: num [1:768, 1] 0.468 -0.365 0.604 -0.92 5.481 ...
..- attr(*, "scaled:center")= num 0.472
..- attr(*, "scaled:scale")= num 0.331
$ age : num [1:768, 1] 1.4251 -0.1905 -0.1055 -1.0409 -0.0205 ...
..- attr(*, "scaled:center")= num 33.2
..- attr(*, "scaled:scale")= num 11.8
$ diabetes: Factor w/ 2 levels "pos","neg": 2 1 2 1 2 1 2 1 2 2 ...22.5 模型建立
22.5.1 数据划分
set.seed(123)
# 随机抽取70%的行索引
ind <- sample(1:nrow(pimadiabetes), size = 0.7 * nrow(pimadiabetes))
# 划分数据集-注意class包在进行要去掉真实值列,kknn包则不需要
train <- pimadiabetes %>%
slice(ind)
test <- pimadiabetes %>%
slice(-ind)
# 将真实值单独提取
truth_train <- pimadiabetes[ind, "diabetes"]
truth_test <- pimadiabetes[-ind, "diabetes"]22.5.2 模型建立
# 计算混淆矩阵
caret::confusionMatrix(fit$fitted.values, truth_test)Confusion Matrix and Statistics
Reference
Prediction pos neg
pos 131 34
neg 19 47
Accuracy : 0.7706
95% CI : (0.7109, 0.8232)
No Information Rate : 0.6494
P-Value [Acc > NIR] : 4.558e-05
Kappa : 0.4738
Mcnemar's Test P-Value : 0.05447
Sensitivity : 0.8733
Specificity : 0.5802
Pos Pred Value : 0.7939
Neg Pred Value : 0.7121
Prevalence : 0.6494
Detection Rate : 0.5671
Detection Prevalence : 0.7143
Balanced Accuracy : 0.7268
'Positive' Class : pos
Call:
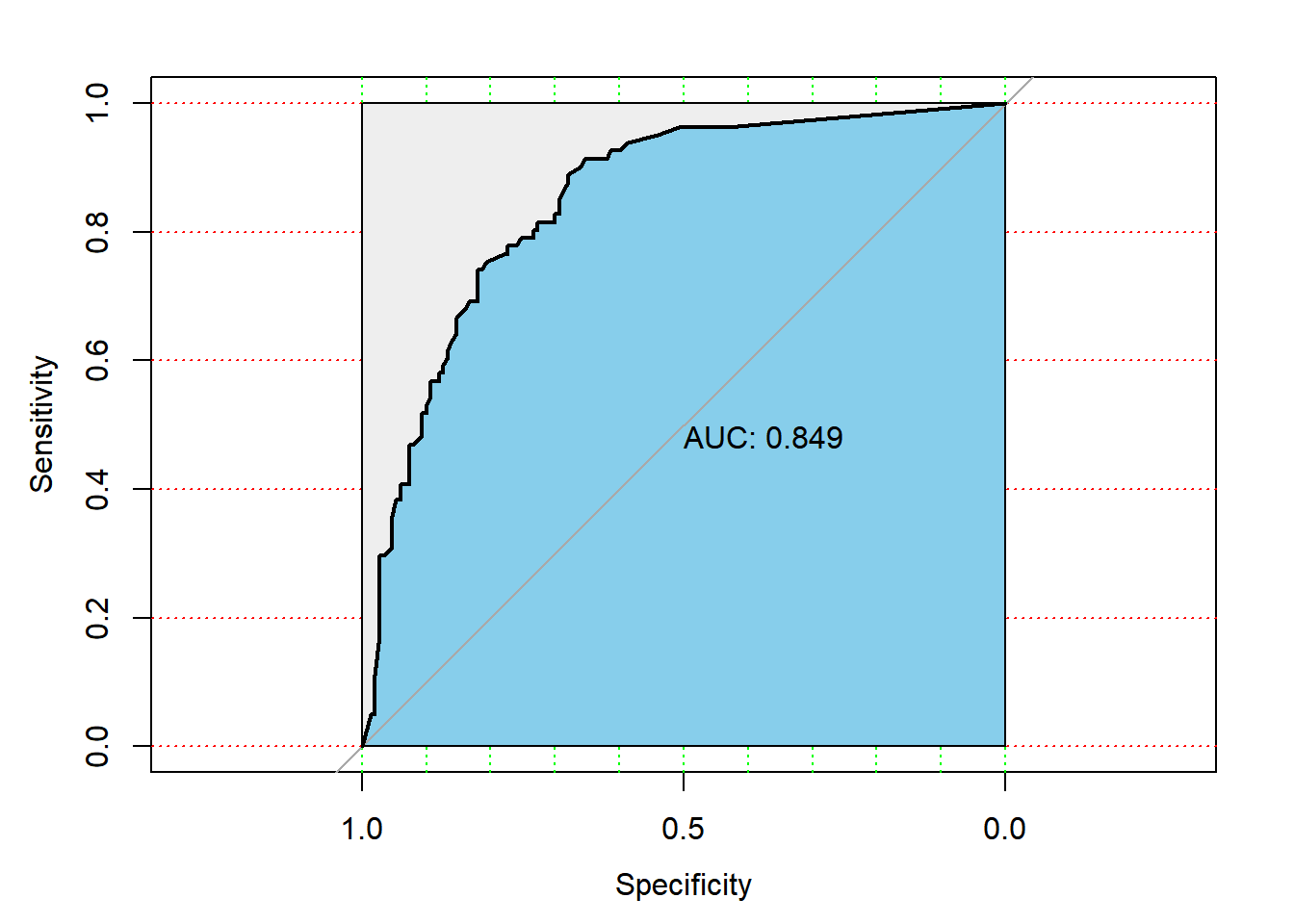
roc.default(response = truth_test, predictor = fit$prob[, 1])
Data: fit$prob[, 1] in 150 controls (truth_test pos) > 81 cases (truth_test neg).
Area under the curve: 0.8491## 绘制
plot(
roc,
print.auc = TRUE,
auc.polygon = TRUE,
max.auc.polygon = TRUE,
auc.polygon.col = "skyblue",
grid = c(0.1, 0.2),
grid.col = c("green", "red"),
print.tres = TRUE
)
输出的结果非常全面,包括:
- 混淆矩阵
- 准确率(accuracy)和准确率的置信区间。
- 无信息率(No Information Rate)和p值。
- Kappa值,Kappa一致性指数。
- 灵敏度(sensitivity)和特异度(specificity)。
- 阳性预测值、阴性预测值
- 流行率(Prevalence)
- 检出率(Detection Rate) -(Detection Prevalence)
- 均衡准确率(Balanced Accuracy)
- 参考类别为Positive class:“‘Positive’ Class : pos”
22.5.3 超参数调优
KNN算法只有一个超参数,就是近邻的数量k。 现在有很多好用的工具可以实现调优过程了,比如 caret、tidymodels、mlr3 等,但是这里演示使用e1071包实现超阐述调优的过程。
library(e1071)
set.seed(123)
tune.knn(
x = train[, -9], # 预测变量
y = truth_train, # 真实值
k = 1:50
) # 近邻的数量
Parameter tuning of 'knn.wrapper':
- sampling method: 10-fold cross validation
- best parameters:
k
25
- best performance: 0.2198113 以上结果直接给出了最佳的k值为25,默认使用10折交叉验证。
22.6 tidymodels进行knn分析-实战案例
?sec-modeling-basics 中详细介绍了使用
tidymodels建立模型的一般步骤选择WineData数据集进行实战案例,使用数据集中的总硫含量(total_sulfur_dioxide)和酸度(acidity)两个变量对红酒颜色(wine_color)进行分类预测。
22.6.1 数据准备
data_wine <- read_rds(
"D:/Document/0.Study R/6.Tidymodels-with-R/data/WineData.rds"
) |>
janitor::clean_names() |>
select(wine_color, acidity, sulrfur = total_sulfur_dioxide) |>
mutate(wine_color = as.factor(wine_color))
head(data_wine)# A tibble: 6 × 3
wine_color acidity sulrfur
<fct> <dbl> <dbl>
1 red 10.8 37
2 white 6.4 213
3 white 9.4 139
4 white 8.2 90
5 white 6.4 183
6 red 6.7 38# 数据划分
set.seed(876)
split7030 <- initial_split(data_wine, prop = 0.7, strata = wine_color)
data_train <- training(split7030)
data_test <- testing(split7030)22.6.2 数据预处理-recipe
recipe_knn_wine <- recipe(wine_color ~ ., data = data_train) |>
step_naomit() |> # 标准化
step_normalize(all_predictors()) # 缺失值处理
recipe_knn_wine
22.6.3 如何选择何时该dplyr或recipes?
- 一般情况下,
tidymodels建议使用recipes进行数据预处理,因为recipes是可重复的,可以在其他数据集上使用。 - 在使用
recipes前,最好可以使用select()函数选择需要的变量,以避免不必要的变量干扰模型,也可以使用.符号选择所有变量。 - 如果需要对结果变量进行转换,建议在
recipes外转换。例如上述代码中,将wine_color转换为factor类型。
22.6.4 模型建立-parsnip
spec_knn_wine <- nearest_neighbor(
neighbors = 4,
# weight_func = "rectangular"
) |>
set_engine("kknn") |>
set_mode("classification")
spec_knn_wineK-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 4
Computational engine: kknn 22.6.5 建立工作流-workflow
# 建立工作流
wf_knn_wine <- workflow() |>
add_recipe(recipe_knn_wine) |>
add_model(spec_knn_wine)
wf_knn_wine══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: nearest_neighbor()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_naomit()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
K-Nearest Neighbor Model Specification (classification)
Main Arguments:
neighbors = 4
Computational engine: kknn # 训练/拟合模型
fit_knn_wine <- wf_knn_wine |>
fit(data_train)
fit_knn_wine══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: nearest_neighbor()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_naomit()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Call:
kknn::train.kknn(formula = ..y ~ ., data = data, ks = min_rows(4, data, 5))
Type of response variable: nominal
Minimal misclassification: 0.09115282
Best kernel: optimal
Best k: 422.6.6 预测-predict
knn_wine_pred <- predict(fit_knn_wine, new_data = data_test)
knn_wine_pred# A tibble: 960 × 1
.pred_class
<fct>
1 white
2 red
3 white
4 white
5 white
6 red
7 white
8 white
9 red
10 red
# ℹ 950 more rows